 |
| This is not a comment on image quality... it is meant to convey us moving forward to new things! |
AMD's FSR 2.0 launched* this week, with its inclusion in Deathloop's latest update and with that comes a multitude of analysis in image quality and performance uplifts. However, while those things aren't really my wheelhouse, there are a few things I thought I'd highlight about FSR 2.0 which are actually publicly available information but appear to be overlooked by many commentators and reviewers out there.
*Whatever "launch" means these days - what with both FSR 1.0 and DirectStorage doing the same thing where you can't actually get the software or source code or documentation unless you're in some sort of super secret partner programme with whoever is developing the software...
 |
| FSR 2.0 performance uplift can be heavily influenced by the specific implementation on the specific hardware the gamer is playing on... For example, this Lanczos look-up table optimisation. What if a developer doesn't implement this. Will certain GPUs perform worse than one might expect? |
FSR 2.0 must be manually tuned...
One aspect I've not seen mentioned by any press thus far is the fact that FSR 2.0 requires some manual tuning for specific architectures and/or GPU variants. It is not the case that having a single setting of quality will scale with compute resources because FSR 2.0 has elements of the processing that are very compute heavy, with multiple passes of compute operations performed on the same data. (See the optimisation of Lanczos lookup tables in the image above).
What this translates to is that these steps in the processing can become bandwidth limited as access time to the data in question becomes the limiting step, rather than the actual compute time itself.
Seeing this, AMD have implemented a control they've dubbed "cache blocking"* which aims to cut up processing operations into smaller batches to help with cache misses. This allows game developers to tailor the algorithm to the idiosyncracies in a specific architecture in order to get the most performance gain and not have precious milliseconds of frametime lost due to increased latency to required frame data.
The problem with this is that it is up to the developer to perform this optimisation...
*Which I think is a terrible name (much like their confusing multiple super resolution features!) because it sounds like a different process is being performed. i.e. it sounds like there's a holding of data in cache... OR a point where there's a processing stop because cache was full, or something. Much like how CPUs and GPUs can stall while waiting for a multithreaded queue or part of a queue to finish before sequential processing can continue...
 |
| If I'm understanding correctly: unless developers perform specific optimisations for a GPU architecture, and even architectural differences between different GPUs within the same generational stack, then a generalised approach will leave specific GPUs as winners or losers in terms of performance gained... |
Even worse, it is up to the developer to optimise for every GPU "die" and architecture for their specific game implementation.
Sure, developers can optimise for a general use case to cut down on development overhead but that means that there will be winners and losers between different GPU architectures... and even within the same product stack!
What is a little concerning is that this is already in evidence at the release of FSR 2.0 in a single game. Sure, there isn't much data to go on at this point and things may change in future (perhaps there will be standardised settings available on GPUOpen for everyone to use but such an implementation might not work across every game/engine depending on the post processing features used) but for now, this is a bit of a flag for developers to keep an eye on - depending on how much they wish to optimise the feature for end-users. You will still achieve better frame rates, just not as high as theoretically possible on specific hardware...
Actually, this point was raised through watching Digital Foundry's analysis on FSR 2.0 where Alex Battaglia found that FSR 2.0 was running slower on AMD's RX 6800 XT in the quality setting at 4K compared to Nvidia's RTX 3080. This struck me as interesting and led me down this rabbit hole to discover the potential reason why.
Checking with the few outlets that have relevant data showed this to be a true result: The absolute magnitude of the difference was different between the outlets but I cannot confirm whether this is down to system-level differences (CPU/RAM) or differences in the tested scene.
 |
| Digital Foundry observed that the Nvidia GPUs they had on hand to test with, processed the FSR algorithm more quickly, per frame, than the AMD cards they had on hand... [Source] |
Looking through the few scant reviews of the technology that included all relevant data, I saw the same trend: The RTX 3080 was outperforming the RX 6800 XT. However, the RTX 3060 Ti was being pummelled by the RX 6700 XT in terms of processing overhead in ComputerBase's results and, as I mentioned above, it is not clear to me whether this is down to them using a 12900K + DDR5 5400 or whether it's the specific scene they tested in the game. Both Digital Foundry and Hardware Unboxed show approximately the same scene in their testing so I'm assuming that their results should be closer based on the level area used for benchmarking - which could account for the difference in the results with CB's data.
 |
| ComputerBase shows an inversion: the RX 6700 XT outperforming the RTX 3060 Ti... [Source] |
 |
| Whereas, Hardware Unboxed showed the RTX 3060 Ti as more performant than the RX 6700 XT... [Source] |
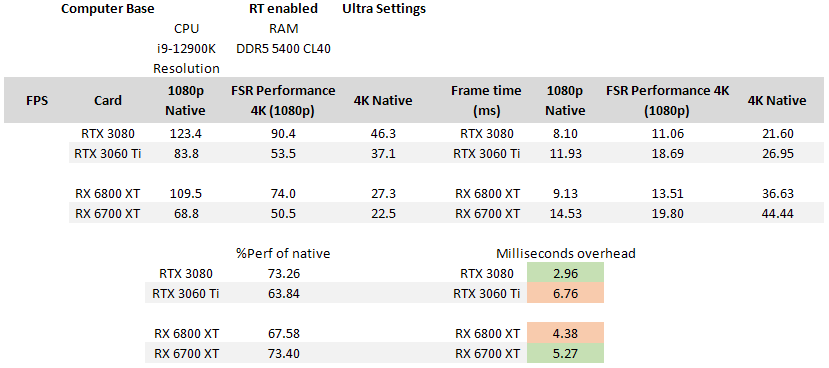 |
| The same trend is repeated at 4K performance vs a native 1080p... |
 |
| There's less data from Hardware Unboxed's analysis but we see something interesting here - essentially equivalent performance for both cards! |
Strange results can also be observed for older architectures as well - strangely, we have more data available in this regard, because this is where Hardware Unboxed chose to focus their extensive investment in time. This is also useful data but gives us a less complete picture as to what's going on in the current architectures of both AMD and Nvidia.
Since 4K was not tested on these older GPUs, I decided to do a slightly different analysis: comparison with 1080p Native resolution performance vs. FSR Performance at 1440p. i.e. 1080p native vs. 960p upscaled to 1440p.
This comparison should show us quite well how CPU/RAM might be limiting the testing between outlets and how much latency the FSR 2.0 algorithm is adding to the processing of each frame.
The results I obtained through this analysis surprised me!
 |
| This was unexpected... The GPUs are rendering at 960p - approx. 79% the pixels of 1080p. |
 |
| This was VERY unexpected... The 6700 XT is rendering faster than Native, even with the overhead of FSR 2.0. |
Back when FSR 1.0 released, I predicted that FSR would be helped by the bandwidth supplied by the presence of the Infinity Cache on the GPU die for RDNA 2. That effect was present, but it was very minor. However, it seems as if the prediction may have come to more fruition with FSR 2.0.
From the (admittedly small) set of data available, it seems as if the FSR 2.0 implementation in Deathloop is potentially optimised for the Navi 32 die architecture, above all else. It could also help explain the inconsistent results for the RX 6700 XT vs RTX 3060 Ti data between ComputerBase and Hardware Unboxed's testing at 4K: in some scenes, it seems like the AMD card might have a bottleneck, reducing performance and this is not observed at 1080p/960p.
Further giving credence to this idea is the data that the RX 6700 XT is the only card that features positive performance in the 1440p Quality setting. Also, looking down to the older GPUs, it is apparent that performance is really quite tied to memory bandwidth.
 |
| The claimed effective bandwidth of the Infinity Caches for both 6800 XT and 6700 XT is used in this analysis... |
Yes, there are differences observed between different architectures having the same bandwidth to the VRAM but that could be explained through lack of compute resources, forced use of less efficient/optimal fallback code paths*, and/or different L0, L1 and L2 cache layouts.
*If my understanding is correct, the Vega cards have a problem because their SIMD are each wave16, which will probably execute slower than the SIMD in Navi (wave32) as the FSR 2 code will execute as wave64 (AMD have indicated as much), and they lack any L1 cache to aid processing latency reduction.
There is still one data point which remains unexplained though...
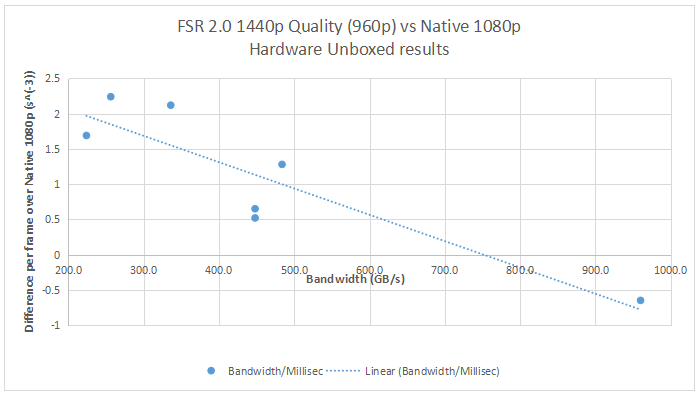 |
| A linear trend is observed between available bandwidth and the added frametime latency for using FSR 2.0 vs native resolution... |
 |
| The trend is linear here for modern architectures, until you take into account the RX 6800 XT which is not acting as we would expect (or even in the ballpark!), given the relationship we've established elsewhere... |
Coming back to that intially interesting result from Digital Foundry - if my supposition that greater bandwidth to data will improve FSR 2.0 performance, why is the RX 6800 XT performing so (relatively) terribly?!
I believe that the answer comes back to one of the problems we have seen plaguing DirectX 12, Vulkan and, now, FSR 2.0: there is some manual tuning or intervention that must be performed in order to get the best performance out of each individual piece of hardware. As such, I believe that the odd, but consistent, results for the RX 6800 XT can be explained as either a bug or oversight in the specific implementation of FSR 2.0.
The question that leads me to now is - how affected by such considerations are the Nvidia cards?
 |
| There are hudreds of permutations possible, so is it possible that the best optimisations are not implemented on certain cards? |
Implementation and adoption...
The issue here is whether the competitors to FSR 2.0 actually have this developmental overhead or not and whether FSR 2.0's overhead is a negative to be held against it. Given that the standardised settings given by AMD are a good place to start, probably not.
However, Nvidia's DLSS does not have any data that looks as "weird" as that presented by tech reviewers so far for FSR 2.0. I haven't gone back yet and performed any sort of deep analysis but it seems like it would have been flagged by now, given all the scrutiny the tech has had over the last few years.
We will also have to see in the coming weeks and months how Intel's XeSS scales on non-Intel hardware... but that's something to look out for!
The ultimate conclusion of this analysis is that the specific implementation/optimisation of FSR 2.0 can and will potentially affect individual GPU architecture/SKU effectiveness within a game, even if it's by accident. Luckily, such an occurrence could be easy to fix but unfortunately, if the developer is seeing that the performance gain is minimal compared to the effort to do it, there likely will be the temptation to not even bother - and I wouldn't blame them.
How many permutations of options would have to be waded through in order to obtain minimal effect on frame times which could be at a global minimum when the currently obtained local minima is sufficient enough to grant that all important boost to performance? Consumers are already getting a performance boost with the technology, do they really need a few fps more?
No comments:
Post a Comment